

holssi 님의 블로그
phoronix 벤치마크로 gcp, ncp 성능 테스트하기 본문
리눅스 벤츠마크로 phoronix를 많이들 쓴다고 한다.
이 툴을 하드웨어 벤치마크와 소프트웨어 벤치마크 모두를 지원한다.
* 하드웨어 벤치마크: cpu, ram대역폭, disk i/o 성능 등을 측정
* 소프트웨어 벤치마크: GCC 컴파일러, Kernel 성능 측정
phoronix 성능측정 결과는 html파일로 저장되고, https://openbenchmarking.org 자동으로 포스팅하는 기능이 있어 여러 사람과 결과를 공유할 수 있음
0. 스펙

1) GCP 서버 생성
- HDD: 표준 영구 디스크, pd-standard 타입 50GB
- SSD: 균형 있는 디스크, pd-balanced 타입 100GB
2) NCP 서버 생성
- 서버 이미지 선택
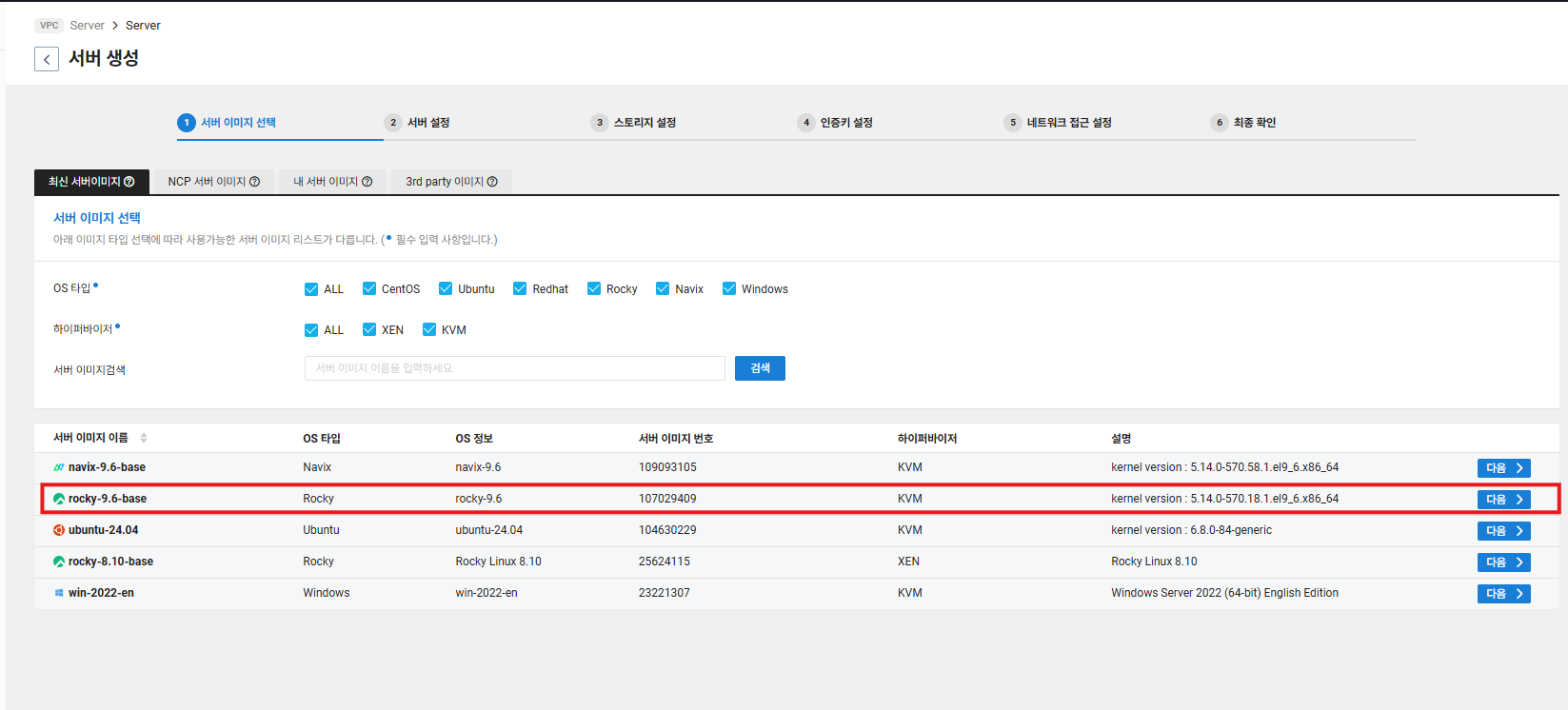
- vpc 생성

- subnect 생성
vpc가 192.168.0.0/16이므로 서브넷을 192.168.1.0/24로 함 (총 256개의 IP를 사용할 수 있음)

- 서버 설정

- 스토리지 설정(cb1 50GB로 함)

- 인증키 설정

- 네트워크 접근 설정

- 공인 ip 부여

- 스토리지 생성
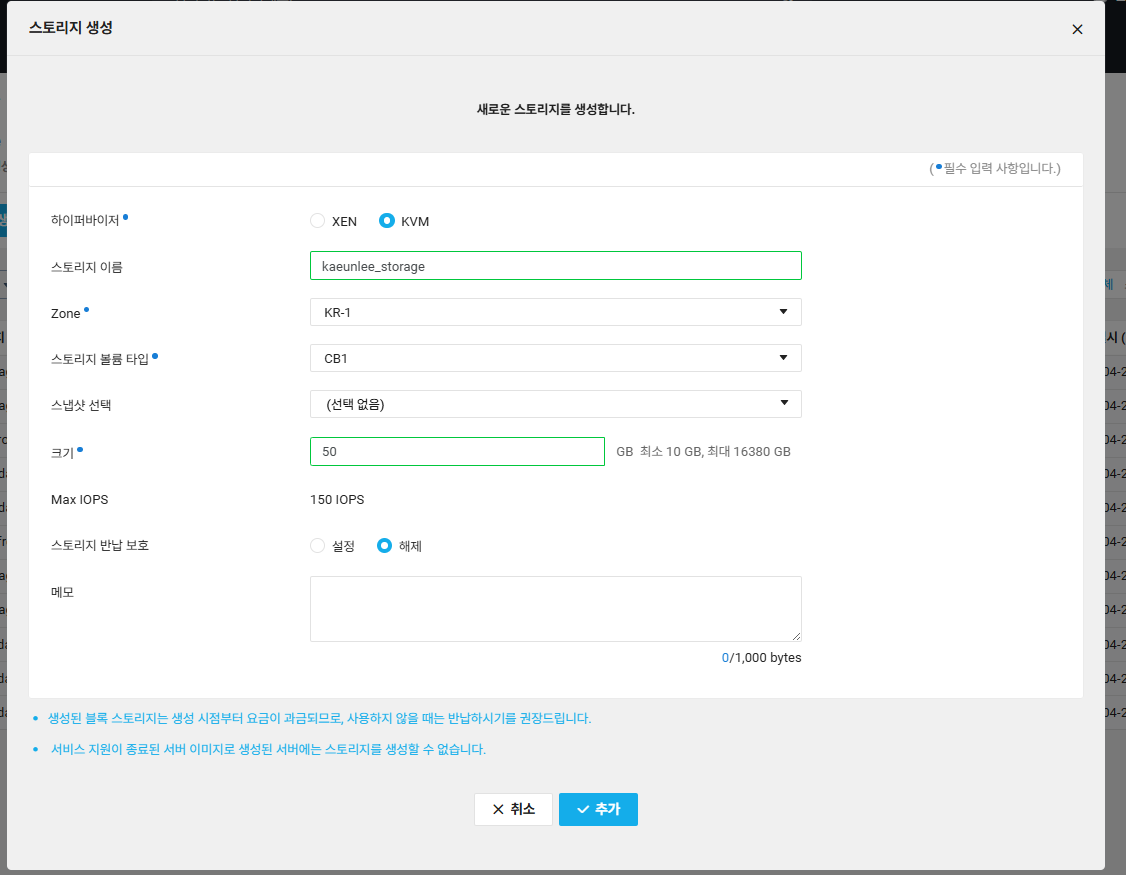
스토리지 설정에 서버 연결
스토리지 생성 후 서버에 연결
1. 파일 시스템 생성
sudo mkfs.xfs /dev/vdb
2. 마운트
sudo mount /dev/vdb /mnt/kaeunlee_storage
3. 연결 확인
df -h | grep kaeunlee_storage
1. phoronix 설치 (gcp)
GitHub - phoronix-test-suite/phoronix-test-suite: The Phoronix Test Suite open-source, cross-platform automated testing/benchmarking software. · GitHub 으로 설치할것이기 때문에 git 설치
PTS 버전은 10.8.6
sudo dnf install git -y
cd ~
git clone https://github.com/phoronix-test-suite/phoronix-test-suite.git
cd phoronix-test-suite
sudo ./install-sh
phoronix-test-suite version
2. phoronix 사용
0) 개발 도구 세트 및 필요한 라이브러리 설치
sudo dnf groupinstall "Development Tools" -y
sudo dnf install epel-release -y
sudo dnf config-manager --set-enabled crb
sudo dnf install nasm yasm p7zip p7zip-plugins unzip php-pecl-zip -yrocky8,9의 crb 이름이 다름 -> rocky8은 powertools이고, rocky9는 crb이다
sudo dnf config-manager --set-enabled powertools
1) 벤치마크 실행이 오래걸릴 수 있으니 tmux 먼저 실행 (터미널 멀티플렉서)
sudo dnf install tmux -y
tmux
2) php 설치
sudo dnf install php-cli php-xml php-json3) 도구 설치
phoronix-test-suite run pts/sqlite
phoronix-test-suite install pts/openssl
4) 벤치마크 실행
phoronix-test-suite run postmark rodinia fftw c-ray compress-gzip x264
* phoronix로 알 수 있는 것들(더 많지만 우선 9개 테스트)
1. 하드웨어 별 성능 지표
| 도구 | 지표 | 설명 | |
| 1 | postmark 1.51 | 디스크 트랜잭션 | 읽고 쓸 때의 속도 |
| 2 | compress-gzip | gzip 속도 | gzip 방식을 이용해 대용량 파일 압축하는데 걸리는 시간 |
| 3 | c-ray | cpu 부동 소수점 연산 능력 | C-Ray 테스트로, Ray Tracing 방식을 이용해 cpu의 순수 멀티코어 부동 소수점 연산 성능 측정하는 벤치마크 - |
| 4 | fftw | cpu 속도 | cpu가 얼마나 빠르게 처리하는지 |
| 5 | rodinia | 병렬 처리 효율 | |
| 6 | x264 | 인코딩 속도 | H.264/AVC를 사용하여 동영상을 인코딩하는 속도를 측정 |
| 7 | stream | 메모리(RAM) 성능 | 메모리의 순차적 읽기/쓰기 성능 측정(순차대역폭) |
| 8 | ramspeed | 메모리(RAM) 성능 | 정수 및 부동 소수점 복사, 가산 등 메모리 대역폭 측정(복합 대역폭) |
| 9 | fio | SSD/HDD 성능 테스트 | 순차/랜덤, 읽기/쓰기 옵션을 세부적으로 테스트 |
| 10 | sqlite | SSD/HDD 성능 테스트 | 애플리케이션에서 데이터 쿼리 속도 처리 측정 |
| 11 | openssl | 암호화 연산 | cpu가 암호화 연산을 얼마나 효율적으로 처리 |
| 12 | kernel | 커널 컴파일 속도 | 리눅스 커널 소스 코드를 실제로 컴파일하는데 걸리는 시간 |
| 13 | thread | 리눅스 스케줄러 성능 | 싱글스레드, 멀티스레드 지연 시간 |
결과
1. gcp
출력결과: https://openbenchmarking.org/result/2604211-NE-KAEUNLEE062
1-1) PostMark 1.51 디스크 트랜잭션 성능 벤치마크 결과
phoronix-test-suite run postmark

평균 성능은 3318TPS이고, 표준 편차별로 0.77%로 일관된 성능 보이고 있음
1-2) 리눅스 커널 소스 트리 압축 테스트 결과
phoronix-test-suite run compress-gzip
gzip 방식을 이용해 대용량 파일 압축하는데 걸리는 시간 -> 63.37초
1-3) cpu 부동 소수점 연산 능력 측정 결과
phoronix-test-suite run c-ray
C-Ray 테스트로, Ray Tracing 방식을 이용해 cpu의 순수 멀티코어 부동 소수점 연산 성능 측정하는 벤치마크 -> 2번 선택
4cp에서 cpu 변별력 확인하기 가장 좋은 해상도
* Ray Tracing 방식: 빛의 물리적인 행동을 시뮬레이션하여 이미지를 만들어내는 렌더링 방식


평균시간: 569.080초, 편차: 0.85%
1-4) fftw(fastest fourier transform in the west) 3.3.6 라이브러리로 cpu가 얼마나 빠르게 처리하는지 테스트
phoronix-test-suite run fftw
주의: 모두 Build: Float+SSE - Size: 2d FFT Size 1024 일때를 함
32~4096까지 1D(1차원), 2D(2차원) 방식 모두 테스트함. 클라우드 서버마다 CPU 캐시 효율이나 메모리 대역폭이 다른데, 어떤 크기의 연산에서 성능 차이가 벌어지는 알 수 있음 -> 2번 선택, 17번 선택
* 1차원(1D), 2차원(2D)는 데이터를 어떤 구조로 배열하고 연산하느냐의 차이
- 1차원(1D)은 데이터를 한 줄로 길게 늘어선 형태
- 2차원(2D)는 데이터가 가로와 세로로 구성된 형태
FFT는 복잡한 신호(데이터)를 여러 개의 단순한 주파수 성분으로 분해하는 수학적 기법임
마지막 사이즈는 데이터 덩어리를 한 묶음으로 처리한다는 뜻

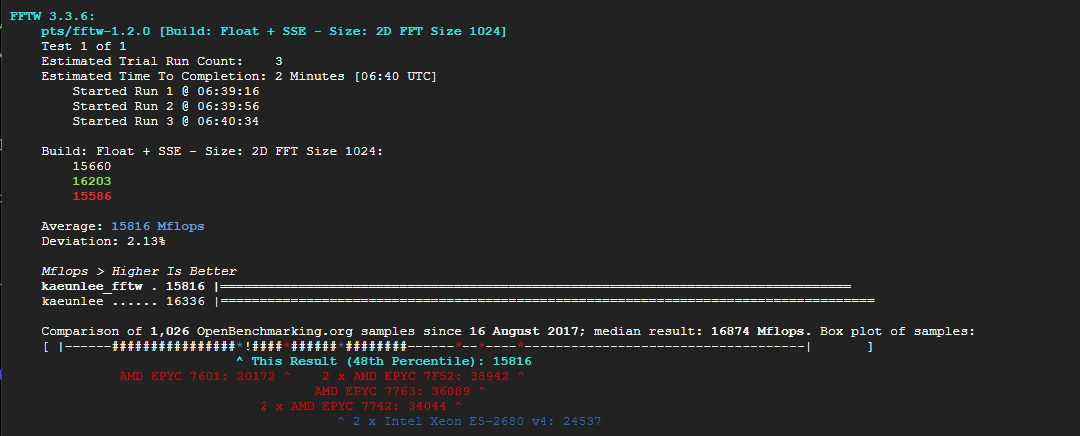
15816 Mflops(Mega Floating-point Operations Per Secound) 초당 181억번의 부동 소수점 연산 수행, 총 샘플수: 12번

1-5) rodinia로 병렬 처리 효율 테스트
phoronix-test-suite run rodinia
Test All Options -> 4번 선택 (데이터마이닝)

4. OpenMP Streamcluster (데이터마이닝 및 클러스터링 성능) -> 56.265초
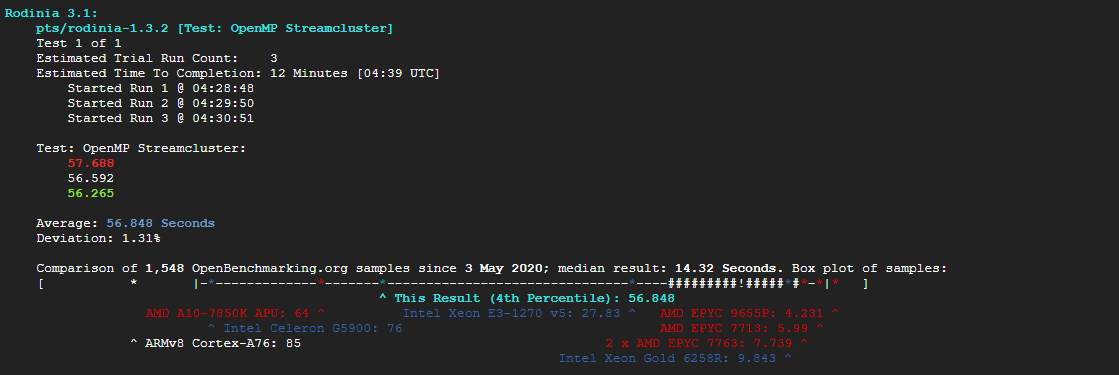
1-6) x264로 H.264/AVC를 사용하여 동영상을 인코딩하는 속도를 측정
phoronix-test-suite run x264
1번 선택


평균 시간: 15.88Frames Per Second
1-7) stream으로 메모리의 순차적 읽기/쓰기 성능 측정(순차대역폭)
phoronix-test-suite run stream

1. Type: Copy (평균속도: 21945.6MB/s)
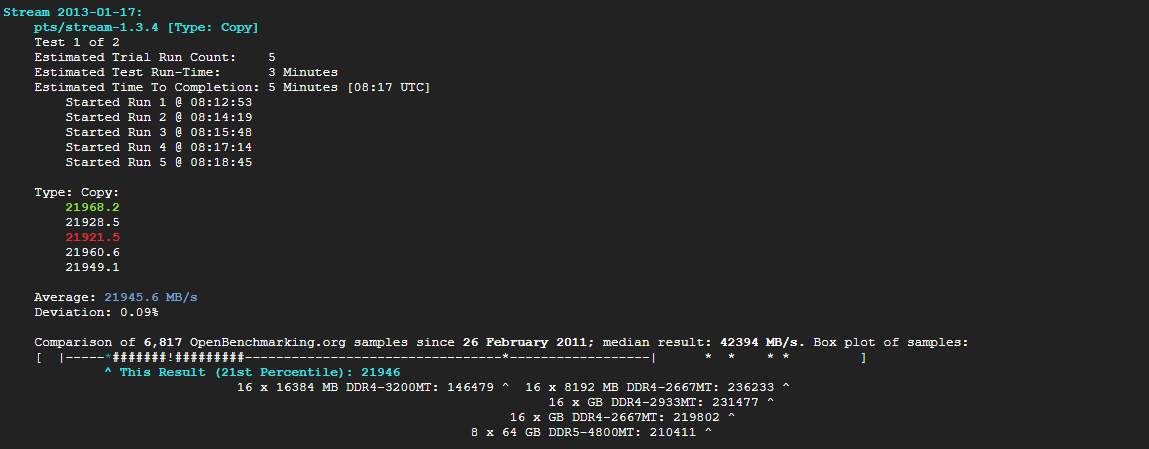
2. Type: Scale (평균속도: 24327.6MB/s)

1-8) 정수 및 부동 소수점 복사, 가산 등 메모리 대역폭 측정(복합 대역폭)
phoronix-test-suite run ramspeed
정수 및 부동 소수점 복사, 가산 등 메모리 대역폭 측정
1. type: add (평균속도: 20.7GB/s)

2. type: copy (평균속도: 20.5GB/s)
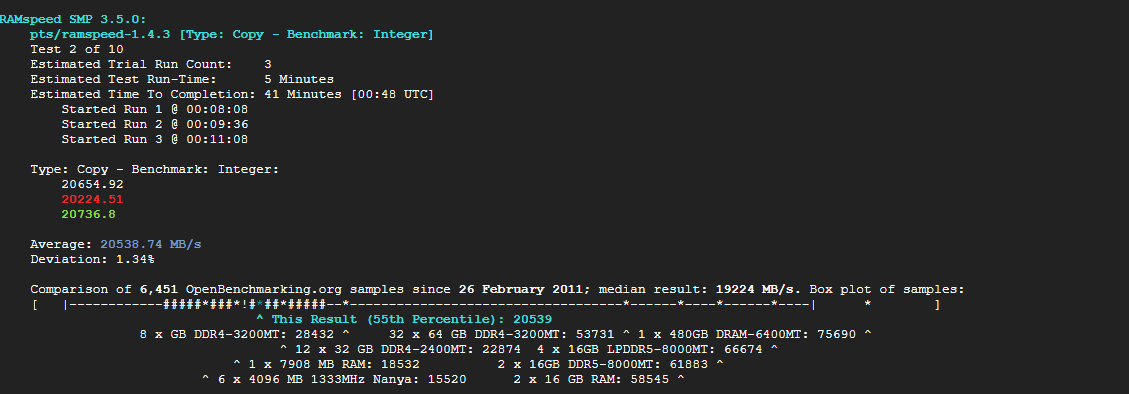
3. type: scale (평균속도: 18.7GB/s)
상수 곱셈 연산 능력

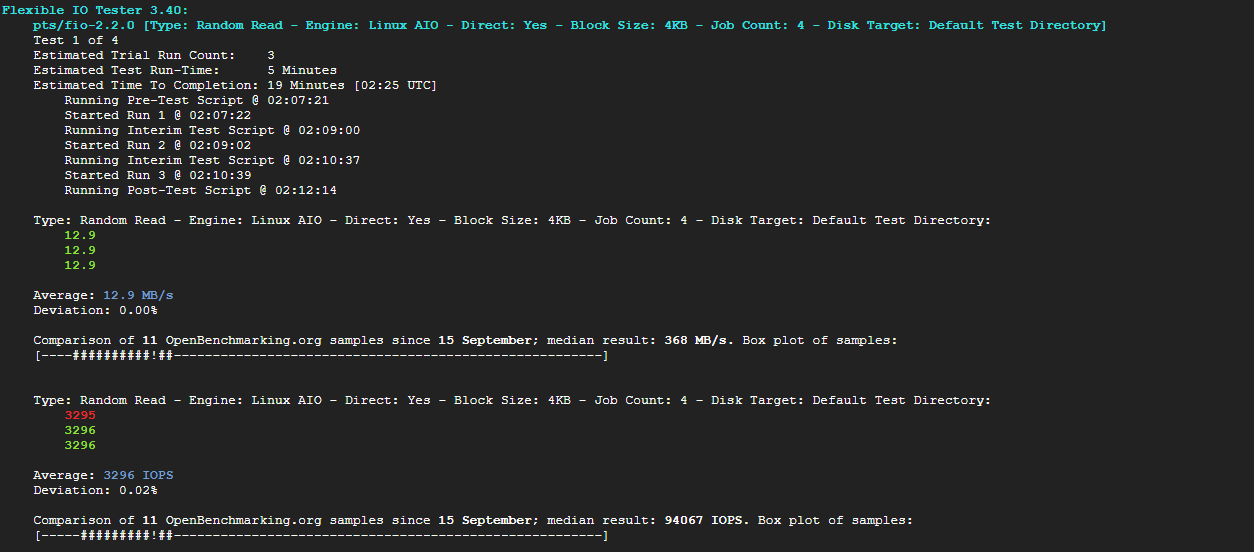
1-9) fio로 순차/랜덤, 읽기/쓰기 옵션을 세부적으로 테스트 - SSD/HDD 나눠서 테스트
[SSD 테스트]
phoronix-test-suite run fio
5번 선택

I/O엔진 선택 -> 4번 선택

Direct를 선택해야 메모리 캐시를 거치지 않고 디스크 순수 성능 측정함, 캐시를 거치면 메모리 속도가 측정되어서 결과가 왜곡됨 -> 2번 선택

작은 파일 처리 능력(4KB IOPS), 큰 파일 전송속도(1MB, MB/s) 확인 -> 1번 선택

동시에 몇개의 작업을 띄울지, vCPU와 개수가 같아야함 -> 3번 선택

1 선택

1. Random Read
12.9MB/s, 3296IOPS

2. Random Write
12.9MB/s, 3291 IOPS

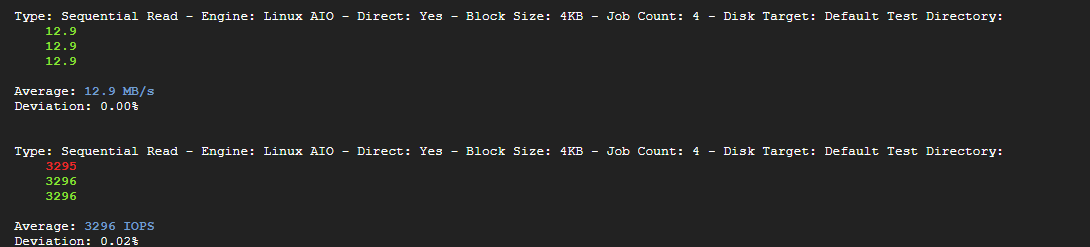
3. Sequential Read
12.9MB/s, 3296 IOPS

4. Sequential Write
12.9MB/s, 3296 IOPS

[HDD 테스트]
1. Random Read
12.9MB/s, 3296 IOPS
2. Random Write
12.9MB/s, 3291 IOPS

3. Sequential Read
12.9MB/s, 3296 IOPS
4. Sequential Write
12.9MB/s, 3296 IOPS

1-10) sqlite로 애플리케이션에서 데이터 읽고 쓰는 작업 성능
phoronix-test-suite run sqlite
4번 선택

[SSD 테스트]
1. copies1 (스레드1) -> 9.053초

2. copies2 (스레드2) -> 9.151초

4. copies4 (스레드4) -> 15.016초

[HDD 테스트]
1. copies1 (스레드1) -> 11.000초
2. copies2 (스레드2) -> 11.255초
4. copies4 (스레드4) -> 14.954초
1-11) openssl로 cpu가 암호화 연산을 얼마나 효율적으로 처리하는지 테스트
phoronix-test-suite run pts/openssl
RHSA4096 선택


서명 성능: 382.4 sign/s, 검증 성능: 25,453.5 verify/s
1-12) build-linux-kernel로 리눅스 커널 소스 컴파일 시간 측정
phoronix-test-suite run build-linux-kernel
deconfig와 allmodconfig는 커널을 구성하는 드라이버나 파일 시스템을 얼마나 많이 포함할지를 결정하는 설정 파일들
1번 선택


927.011초
1-13) hackbench로 싱글스레드와 멀티스레드 일때 지연 시간 테스트
phoronix-test-suite run hackbench
[싱글스레드] 28.859s

[멀티스레드] 59.729s

2. ncp서버1 (kaeunlees4g3)
결과: https://openbenchmarking.org/result/2604215-NE-KAEUNLEE630
2-1) PostMark 1.51 디스크 트랜잭션 성능 벤치마크 결과
phoronix-test-suite run postmark

평균 성능: 3000TPS이고, 표준 편차가 0.69%로 일관된 성능을 보이고 있음
2-2) 리눅스 커널 소스 트리 압축 테스트 결과
phoronix-test-suite run compress-gzip
gzip 방식을 이용해 대용량 파일 압축하는 데 걸리는 시간 -> 60.524초
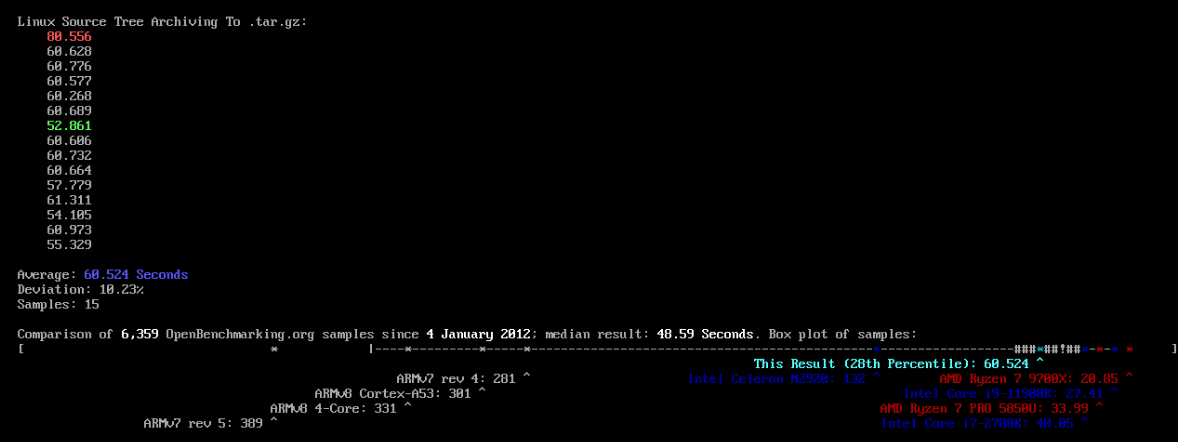
2-3) cpu 부동 소수점 연산 능력 측정 결과
phoronix-test-suite run c-ray

평균 시간: 272.622초
2-4) fftw(fastest fourier transform in the west) 3.3.6 라이브러리로 cpu가 얼마나 빠르게 처리하는지 테스트
phoronix-test-suite run fftw
Build: Float+SSE - Size: 2D FFT size 1024 동일하게 적용

35357 Mflops(Mega Floating-point Operations Per Secound) 초당 181억번의 부동 소수점 연산 수행, 총 샘플수: 12번
2-5) rodinia로 병렬 처리 효율 테스트
phoronix-test-suite run rodinia
4. OpenMP Streamcluster (데이터마이닝 및 클러스터링 성능) -> 136초 소요

2-6) x264로 H.264/AVC를 사용하여 동영상을 인코딩하는 속도를 측정
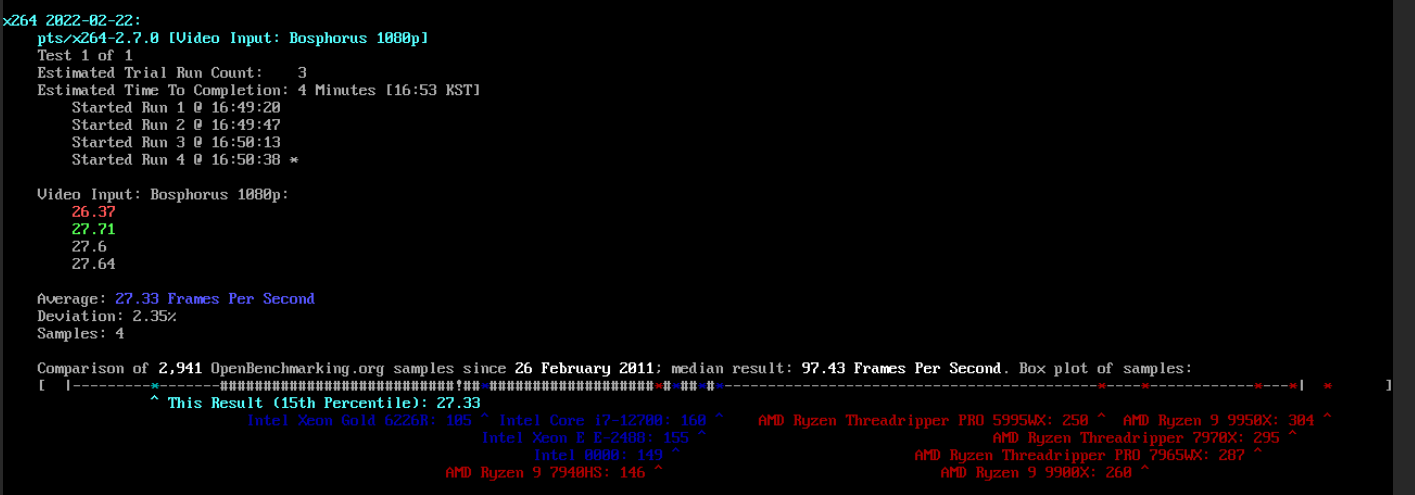
27.33 Frames Per Second
2-7) stream으로 메모리의 순차적 읽기/쓰기 성능 측정(순차대역폭)
phoronix-test-suite run stream
메모리(RAM)에서 데이터를 읽어와 특정 값을 곱한 뒤 다시 쓰는 속도를 측정

1. type: copy (평균속도: 64,480.2GB/s)
2. type: scale (평균속도: 81,082.3GB/s)
2-8) ramspeed로 정수 및 부동 소수점 복사, 가산 등 메모리 대역폭 측정(복합 대역폭)
phoronix-test-suite run ramspeed
정수 및 부동 소수점 복사, 가산 등 메모리 대역폭 측정
1. type: add (평균속도: 52,559.02MB/s)

2. type: copy (평균속도: 49771.72MB/s)

3. type: scale (평균속도: 46668.08MB/s)

2-9) fio로 순차/랜덤, 읽기/쓰기 옵션을 세부적으로 테스트
phoronix-test-suite run fio
[SSD 테스트]
1. Random Read
11.7MB/s, 2998 IOPS
2. Random Write
11.7MB/s, 2993 IOPS
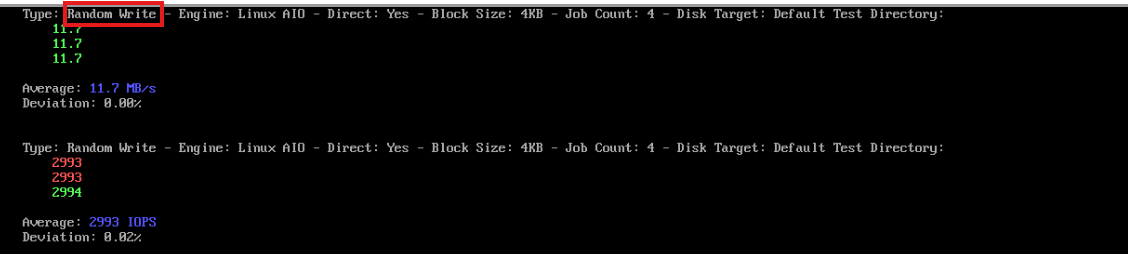
3. Sequential Read
12.6 MB/s, 3227 IOPS

4. Sequential Write
12.4MB/s, 3162 IOPS
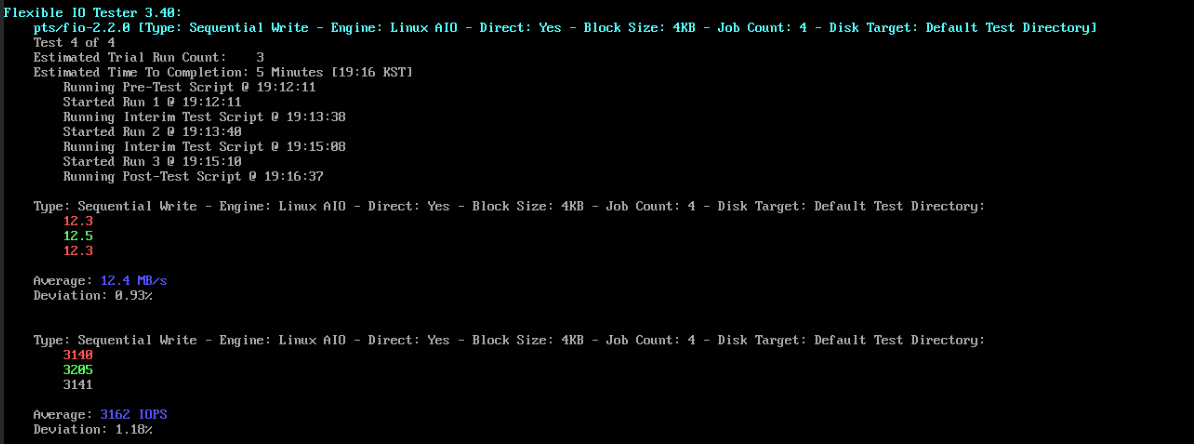
[HDD 테스트]
PTS_USER_PATH=/mnt/kaeunlee_storage phoronix-test-suite run fio
1. Random Read
11.7MB/s, 2998 IOPS

2. Random Write
11.7MB/s, 2994 IOPS

3. Sequential Read
12.6MB/s, 3229 IOPS

4. Sequential Write
8.005MB/s, 2843 IOPS

2-10) sqlite로 애플리케이션에서 데이터 읽고 쓰는 작업 성능
phoronix-test-suite run sqlite (sqlite version: 3.50.4)
[SSD 테스트]
1. copies1 (싱글 테스크) -> 5.041초
2. copies2 (듀얼테스크, 동시에 2명이 작업) -> 9.552초
4. copies4 (멀티테스크, 동시에 4명 작업) -> 16.521초
[HDD 테스트]
1. copies1 (싱글 테스크) -> 5.041초
2. copies2 (듀얼테스크, 동시에 2명이 작업) -> 9.457초
4. copies4 (멀티테스크, 동시에 4명 작업) -> 242.504초
2-11) openssl로 cpu가 암호화 연산을 얼마나 효율적으로 처리하는지 테스트
phoronix-test-suite run pts/openssl

서명 성능: 1420.1sign/s, 검증 성능: 34,000.8verify/s
2-12) build-linux-kernel로 리눅스 커널 소스 컴파일 시간 측정
phoronix-test-suite run build-linux-kernel

506.027초
2-13) hackbench로 싱글스레드와 멀티스레드 일때 지연 시간 테스트
phoronix-test-suite run hackbench
[싱글스레드] 30.617s

[멀티스레드] 48.466s

3. ncp서버 (kaeunleem4g3)
결과: https://openbenchmarking.org/result/2604213-NE-KAEUNLEE686
3-1) PostMark 1.51 디스크 트랜잭션 성능 벤치마크 결과
phoronix-test-suite run postmark

평균 성능: 2976TPS이고, 표준 편차가 0.00%임
3-2) 리눅스 커널 소스 트리 압축 테스트 결과
phoronix-test-suite run compress-gzip

cpu의 정상 연산 능력과 디스크I/O가 복합적으로 작용하는 테스트
평균 시간: 61.66초, 샘플수: 15회


3-3) cpu 부동 소수점 연산 능력 측정 결과
phoronix-test-suite run c-ray

평균 시간: 588.850초
3-4) fftw(fastest fourier transform in the west) 3.3.6 라이브러리로 cpu가 얼마나 빠르게 처리하는지 테스트
phoronix-test-suite run fftw
Build: Float+SSE - Size: 2D FFT size 1024 동일하게 적용

35009 Mflops(Mega Floating-point Operations Per Secound) 초당 181억번의 부동 소수점 연산 수행, 총 샘플수: 12번
3-5) rodinia로 병렬 처리 효율 테스트
phoronix-test-suite run rodinia

OpenMP Streamcluster (데이터마이닝 및 클러스터링 성능) -> 31.124초
3-6) x264로 H.264/AVC를 사용하여 동영상을 인코딩하는 속도를 측정

평균속도: 24.99 Frames Per Second
3-7) stream으로 메모리의 순차적 읽기/쓰기 성능 측정(순차대역폭)
1. type: copy (평균속도: 144099.3GB/s)
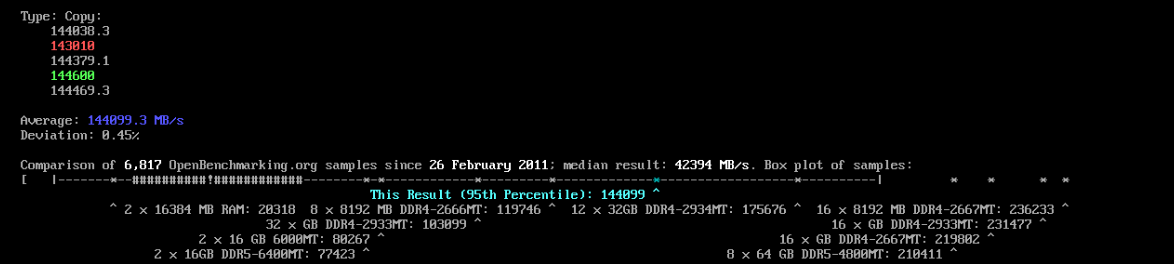
2. type: scale (평균속도: 144456.2GB/s)

3-8) ramspeed로 메모리 성능 테스트
phoronix-test-suite run ramspeed
정수 및 부동 소수점 복사, 가산 등 메모리 대역폭 측정
1. type: add (평균속도: 66428.60MB/s)

2. type: copy (평균속도: 65423.50MB/s)

3. type: scale (평균속도: 65596.98MB/s)

3-9) fio로 순차/랜덤, 읽기/쓰기 옵션을 세부적으로 테스트
phoronix-test-suite run fio
[SSD 테스트]
1. Random Read
11.7MB/s, 2998 IOPS

2. Random Write
11.7MB/s, 2992 IOPS

3. Sequential Read
12.7MB/s, 3261 IOPS

4. Sequential Write
12.4MB/s, 3162 IOPS

[HDD 테스트]
PTS_USER_PATH=/mnt/kaeunlee_storage2 phoronix-test-suite run fio
1. Random Read
11.7MB/s, 2998 IOPS

2. Random Write
11.7MB/s, 2995 IOPS

3. Sequential Read
13.2MB/s, 3377 IOPS

4. Sequential Write
5.507MB/s, 1408 IOPS

3-10) sqlite로 애플리케이션에서 데이터 읽고 쓰는 작업 성능
[SSD 테스트]
phoronix-test-suite run sqlite
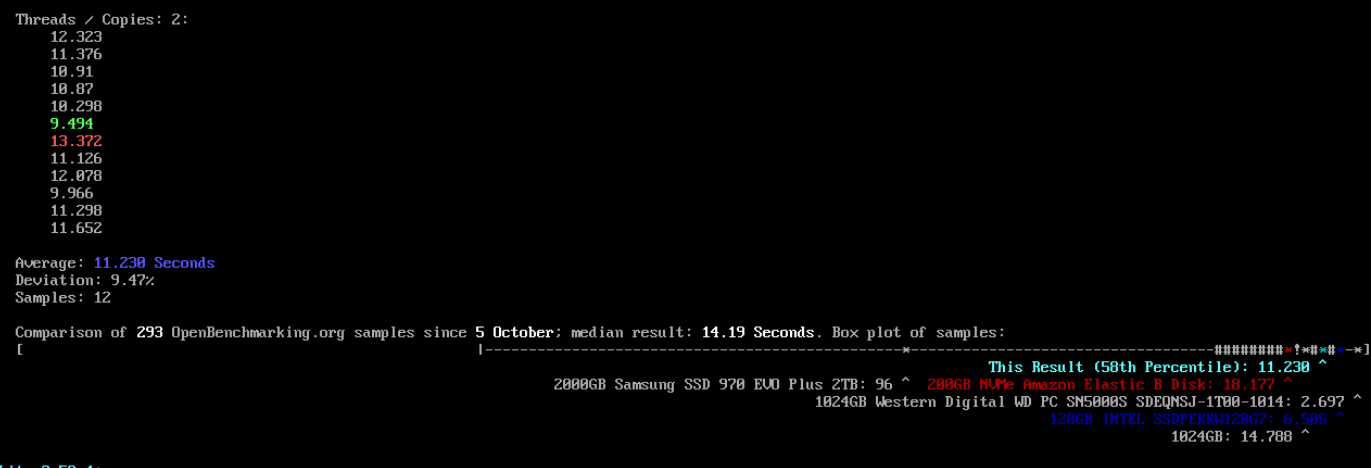
1. copies1 (싱글 테스크) -> 7.511초

2. copies2 (듀얼테스크, 동시에 2명이 작업) -> 11.230초
4. copies4 (멀티테스크, 동시에 4명 작업) -> 17.874초
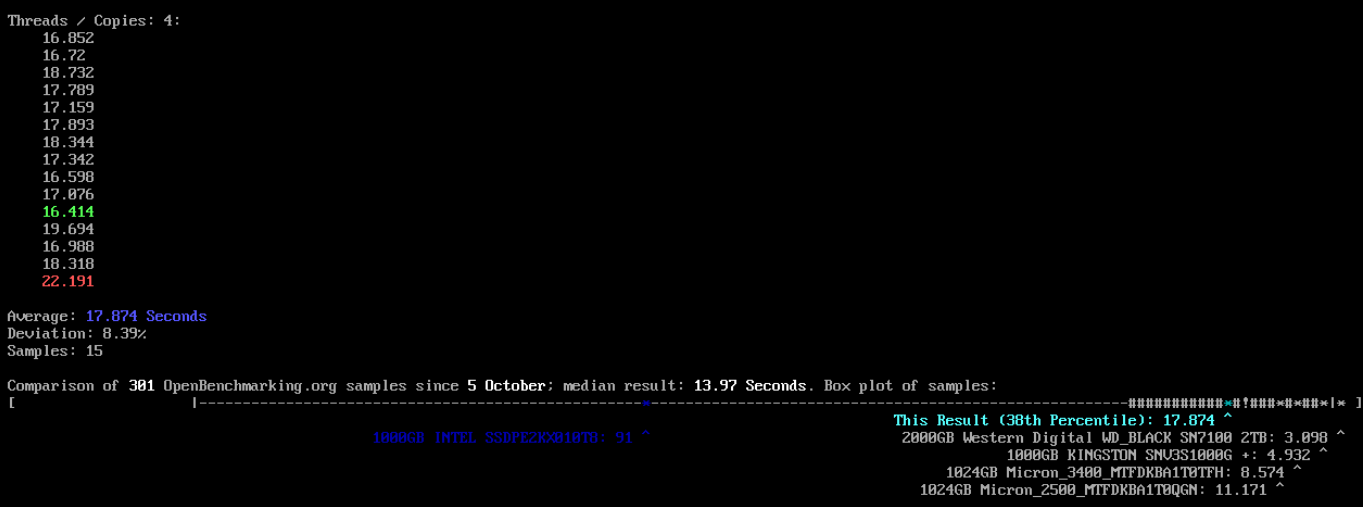
[HDD 테스트]
1. copies1 (싱글 테스크) -> 7.511초
2. copies2 (듀얼테스크, 동시에 2명이 작업) -> 9.511초
4. copies4 (멀티테스크, 동시에 4명 작업) -> 236.421초
3-11) openssl로 cpu가 암호화 연산을 얼마나 효율적으로 처리하는지 테스트
phoronix-test-suite run pts/openssl

서명 성능: 2823.2sign/s,
검증 성능: 67920.9verify/s
3-12) build-linux-kernel로 리눅스 커널 소스 컴파일 시간 측정
phoronix-test-suite run build-linux-kernel

273.184초
3-13) hackbench로 싱글스레드와 멀티스레드 일때 지연 시간 테스트
phoronix-test-suite run hackbench
[싱글스레드] 16.437s

[멀티스레드] 33.199s

정리
1. cpu
| 테스트 종류 | 설명 | GCP | NCP | NCP | 우위 |
| 서버이름 | kaeunleetest | kaeunleems4g3 | kaeunleem4g3 | ||
| 스펙 | vCPU4, 24GB, 50GB | vCPU4, 32GB, 50GB(cb1) | vCPU4, 16GB, 50GB(cb1) | ||
| hackbench | 싱글스레드, 멀티스레드 지연 시간 테스트 | 싱글스레드: 28.859s 멀티스레드: 59.729s |
싱글스레드: 30.617s 멀티스레드: 48.466s |
싱글스레드: 16.437s 멀티스레드: 33.199s |
NCP(값이 작을수록) |
| compress- zip |
cpu의 정상 연산 능력과 디스크I/O의 복합적인 성능 | 63.37초 | 60.524초 | 61.66초 | 큰 차이 없음 |
| c-ray | cpu 부동 소수점 연산 능력과 멀티코어 효율 | 569.080초 | 60.524초 | 588.850초 | NCP S4G3(값이 작을수록) |
| fftw | 수학적 변환과 메모리 대역폭 테스트 | 15816 Mflops | 35357 Mflops | 35009 Mflops | NCP |
| rodinia | 병렬 처리 효율 테스트 | OpenMP Streamcluster (데이터마이닝 및 클러스터링 성능) -> 56.265초 | OpenMP Streamcluster (데이터마이닝 및 클러스터링 성능) -> 136초 | OpenMP Streamcluster (데이터마이닝 및 클러스터링 성능) -> 31.124초 | NCP M4G3(값이 작을수록) |
| x264 | H.264/AVC를 사용하여 동영상을 인코딩하는 속도를 측정 | 15.88Frames/s | 27.33 Frames/s | 24.99 Frames/s | NCP S4G3(값이 클수록) |
- fftw(cpu) 속도는 ncp가 35,000 Mflops 수준으로 GCP보다 2배 이상 빠르고, 부동 소수점 연산 능력이 훨씬 뛰어남
- c-ray(부동소수점 연산)은 ncp s4g3이 60.524초로 압도적으로 빠름
- x264(동영상 인코딩)은 ncp s4g3(27.33) > ncp m4g3(24.99) > gcp(15.88) 순으로 성능 차이가 남
2. memory
| GCP | NCP(s4g3) | NCP(m4g3) | 우위 | ||
| stream | 메모리의 순차적 읽기/쓰기 성능 측정(순차대역폭) | - copy (21945.6MB/s) - scale (24327.6MB/s) |
- copy (64,480.2GB/s) - scale (81,082.3GB/s) |
- copy (144099.3GB/s) - scale (144456.2GB/s) |
NCP |
| ramspeed | 정수 및 부동 소수점 복사, 가산 등 메모리 대역폭 측정 | - add (20.7GB/s) - copy (20.5GB/s) - scale (18.7GB/s) |
- add (52,559.02MB/s) - copy (49771.72MB/s) - scale (46668.08MB/s) |
- add (66428.60MB/s) - copy (65423.50MB/s) - scale (65596.98MB/s) |
NCP(2~3배 차이) |
- stream(순차 읽기/쓰기): ncp가 64,000~144,000MB/s 높은 대역폭임
- ramspeed(복사/가산): ncp가 gcp보다 2~3배 이상 높은 속도 유지
3. 디스크 I/O 성능
| GCP | NCP(s4g3) | NCP(m4g3) | 우위 | ||
| postmark | 디스크 트랜잭션 성능 | 3318TPS | 3000TPS | 2976TPS | 큰 차이 없음(GCP) |
| fio | SSD | - Random Read 12.9MB/s, 3296IOPS - Random Write 12.9MB/s, 3291 IOPS - Sequential Read 12.9MB/s, 3296 IOPS - Sequential Write 12.9MB/s, 3296 IOPS |
- Random Read 11.7MB/s, 2998 IOPS - Random Write 11.7MB/s, 2993 IOPS - Sequential Read 12.6 MB/s, 3227 IOPS - Sequential Write 12.4 MB/s, 3162 IOPS |
- Random Read 11.7MB/s, 2998 IOPS - Random Write 11.7MB/s, 2992 IOPS - Sequential Read 12.7MB/s, 3261 IOPS - Sequential Write 12.4MB/s, 3162 IOPS |
큰 차이 없음 |
| HDD | - Random Read 12.9MB/s, 3296 IOPS - Random Write 12.9MB/s, 3291 IOPS - Sequential Read 12.9MB/s, 3296 IOPS - Sequential Write 12.9MB/s, 3296 IOPS |
- Random Read 11.7MB/s, 2998 IOPS - Random Write 11.7MB/s, 2995 IOPS - Sequential Read 12.6MB/s, 3229 IOPS - Sequential Write 8.0MB/s, 2843 IOPS |
- Random Read 11.7MB/s, 2998 IOPS - Random Write 11.7MB/s, 2995 IOPS - Sequential Read 13.2MB/s, 3377 IOPS - Sequential Write 5.507MB/s, 1408 IOPS |
큰 차이 없음 |
- postmark(트랜잭션): 모두 3000TPS로 디스크의 기본적인 초당 처리량은 큰 차이 없음
- fio(랜덤/순차 읽기 쓰기): 모두 약 12MB/s, 3200IOPS로 큰 차이 없음
4. 애플리케이션 및 암호화 성능
| GCP | NCP(s4g3) | NCP(m4g3) | 우위 | ||
| sqlite | SSD | - copies1(9.053초) - copies2(9.151초) - copies4(15.016초) |
- copies1(5.041초) - copies2 (9.552초) - copies4 (16.521초) |
- copies1 (7.511초) - copies2 (11.230초) - copies4 (17.874초) |
GCP |
| HDD | - copies1(11.000초) - copies2(11.255초) - copies4(14.954초) |
||||
| openssl | cpu가 암호화 연산을 얼마나 효율적으로 처리 | 서명 성능: 382.4 sign/s, 검증 성능: 25,453.5 verify/s |
서명 성능: 1420.1sign/s, 검증 성능: 34,000.8verify/s |
서명 성능: 2823.2sign/s, 검증 성능: 67920.9verify/s |
NCP S4G3 |
| kernel | 리눅스 커널 소스 컴파일 시간 측정 | 927.011초 | 506.027초 | 273.184초 |
- sqlite(데이터 쿼리): 단일 쿼리 중심 작업이면 ncp의 s4g3이 가장 유리하고, 동시 접속 및 다중 쿼리 비중이 높다면 gcp가 우세하긴 하나 큰 차이 없음
- openssl(암호화): 서명 및 검증 성능에서 ncp m4g3이 가장 뛰어남. gcp 대비 약 7배 이상의 성능 차이(cpu에 내장된 암호화 가속 명령어(AES-NI)의 지원 여부 차이로 보임)
- kernel(커널 컴파일 속도):
* gcp와 ncp가 sqlite 테스트에서 각각 다른 현상이 보인 이유
gcp는 스레드가 늘어날수록 성능이 떨어지고, ncps는 스레드가 늘어날수록 성능 상승
스토리지를 처리하는 방식(I/O 아키텍처)과 가상화 자원 할당 정책의 차이 때문임
GCP 결과는 (9.053초-> 9.151초-> 15.016초) 으로 자원 제한 현상을 보임. 1개 스레드일때는 속도가 빠르고 이는 GCP의 기본 스토리지 레이턴시가 매우 낮음. 그러나 4개 스레드로 늘어났을때 시간이 1.6배로 늘어남.
GCP의 Persistent Disk(PD) 성능은 vCPU 개수와 비례하여 할당함. 즉, 4개 스레드가 동시에 I/O 요청을 하면 설정된 최대 처리량 한도에 걸리게 됨
NCP결과는 (296.73초-> 222.12초 -> 28.47초) 으로 대역폭 중심의 스토리지 설정과 파일 시스템 캐시 활용을 보여줌
단일쓰기 작업시 물리적인 디스크 쓰기 확정(commit) 시간이 길거나, 네트워크 스토리지의 기본 지연 시간이 길다
NCP는 한꺼번에 요청이 들어오면 이를 병렬로 묶어 처리하는 방식(Deep Queue Depth)에 최적화되어 있을 가능성이 높고, 스레드가 늘어날 때 운영체제나 클라우드 하이퍼바이저 레벨에서 쓰기 버퍼(cache)를 더 공격적으로 활용
* fftw로 성능 테스트시 Mflops 초당 181억번의 부동 소수점 연산 수행 결과가 GCP, NCP가 거의 2.2배 차이가 나는 이유
같은 vCPU 4개임에도 불구하고 약 2.2배의 차이가 나는 이유는 FFT 연산은 CPU의 IPC(클록당 명령어 처리 횟수)와 자원 할당 방식이 다르기 때문이다
1. cpu 아키텍처의 세대 차이
GCP E2의 skylake나 Rome(Zen 2)은 NCP에서 사용하는 lce Lake(Intel 3세대 Xeon) 보다 구형 아키텍처이다
NCP g3은 Intel Xeon Scalable 3세대(Ice Lake)는 이전 세대 대비 부동 소수점 연산 효율이 향상되어서 클록 속도가 같더라도 한 번의 사이클에 처리할 수 있는 수학 계산량이 훨씬 많다
Build를 Float+SSE - Size: 20 FTT Size 1024로 했는데, 이때 SSE(Streaming SIMD Extensions)는 한번의 명령으로 여러 데이터를 동시에 처리하는 기술이다. NCP의 3세대 제온은 병렬 연산 최적화가 GCP의 가변 사양보다 훨씬 강력하게 작동하여, FFT 같은 대량 연산에서 높은 수치를 기록한다
GCP E2는 물리 코어 하나를 온전히 주는게 아니라 여러 사용자가 자우너을 나누어 쓰는 자원 오버커밋 방식을 사용함. 이 과정에서 다른 사용자의 부하에 영향을 받거나 CPU 터보 부스트 클록이 제한될 수 있음
NCP g3은 비교적 최신 고사양 하드웨어 풀에서 자원을 할당받으므로, 연산 집약적인 작업 시 더 높은 클록 주파수를 안정적으로 유지함
결과 파일 및 로컬로 가져오기
phoronix-test-suite list-results
phoronix-test-suite pdf-test-results kaeunlee
gcloud compute scp --recurse kaeunleetest:~/.phoronix-test-suite/test-results/kaeunlee ./kaeunlee_results --zone=asia-northeast3-a
'SERVER' 카테고리의 다른 글
| yum clean all 실패 해결 (0) | 2026.05.04 |
|---|---|
| PTS로 NCP 성능 테스트 결과 (0) | 2026.04.23 |
| phoronix-test-suite run pts/openssl시 No targets specified and no makefile found 에러와 해결 (1) | 2026.04.21 |
| [Linux] 리눅스 파일시스템과 /etc/fstab (0) | 2026.04.19 |
| [Linux] 리눅스 파일시스템과 /etc/exports (0) | 2026.04.19 |